
Paper Review stellen wir euch aktuelle Paper aus dem Bereich Machine Learning vor. Wir fassen für euch das Wesentliche zusammen und ihr entscheidet selbst, ob ihr das Paper lesen wollt oder nicht. Viel Spaß!
Was ist neu
Die Autoren präsentieren einen Ansatz, der Deep Learning für den klassischen Named Entity Task benutzt. Dabei geht es darum, Orte, Personen und andere Entitäten in Texten zu finden. Außerdem stellen sie mit BRAT einen visuellen Annotator vor. Hier gehts zum Paper.Worum geht es
[caption id="attachment_308" align="alignright" width="507"]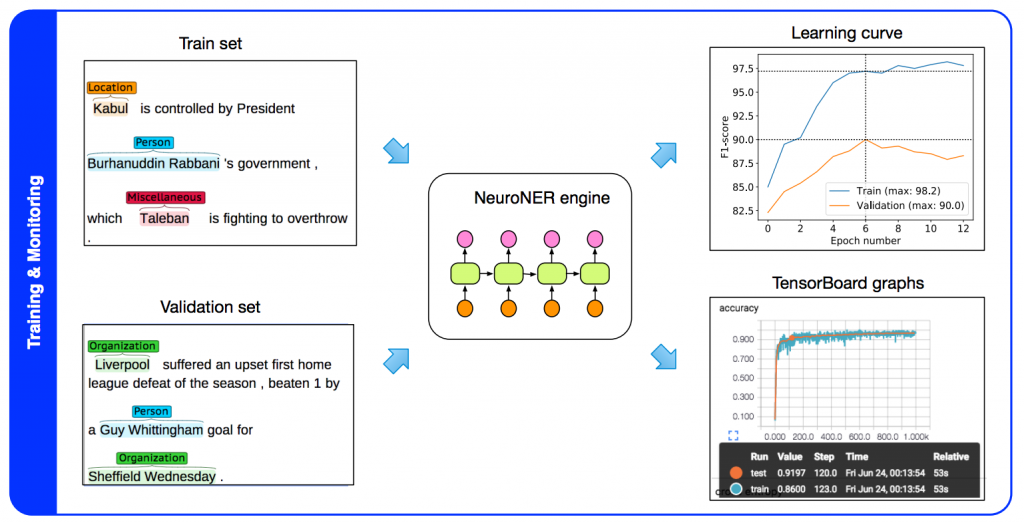 Trainingsprozess von NeuroNER. Figure 1 aus NeuroNER: an easy-to-use program for named-entity recognition based on neural networks[/caption]
Named Entity Recognition ist eine Aufgabe, die meist auf Corpora beruht, die mühevoll annotiert wurden. Diese Corpora werden in Modelle umgewandelt und meist nicht mitgeliefert. Das macht eine erneute Annotation beziehungsweise eine erweiterte Annotation sowie ein darauf folgendes Re-Training der Modelle unmöglich. NeuroNER bietet diese Möglichkeit. Es besteht aus 2 Komponenten:
Trainingsprozess von NeuroNER. Figure 1 aus NeuroNER: an easy-to-use program for named-entity recognition based on neural networks[/caption]
Named Entity Recognition ist eine Aufgabe, die meist auf Corpora beruht, die mühevoll annotiert wurden. Diese Corpora werden in Modelle umgewandelt und meist nicht mitgeliefert. Das macht eine erneute Annotation beziehungsweise eine erweiterte Annotation sowie ein darauf folgendes Re-Training der Modelle unmöglich. NeuroNER bietet diese Möglichkeit. Es besteht aus 2 Komponenten:
- NeuroNER Modell – Ein Deep Learning Netz, basierend auf einer bestimmten Variante von RNNs (Recurrent Neural Networks) die sogenannten LSTM (Long Short Term Memory) mit 3 Ebenen: Character-enhanced token-embedding layer, Label prediction layer & Label sequence optimization layer.
- BRAT – Ein webbasiertes Annotations-Tool für Trainingsdaten. Das Tool ermöglicht es, sehr schnell neue Annotationen zum Korpus hinzuzufügen.
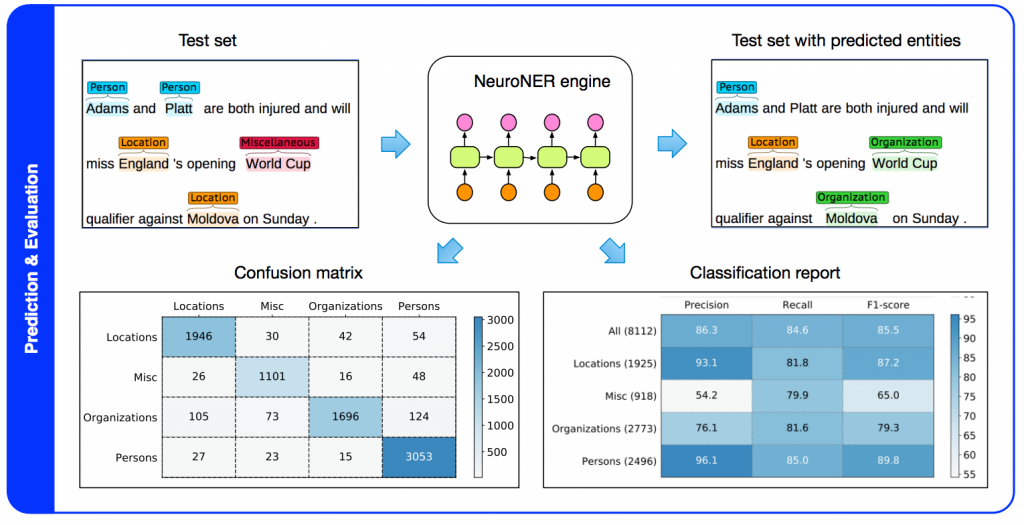 Prediction und Evaluation. Figure 1 von NeuroNER: an easy-to-use program for named-entity recognition based on neural networks[/caption]
Bei NeuroNER liegt der Fokus auf Usability. Durch ihr Annotationstool und die enge Verzahnung zum Modelltraining gelingt das den Autoren auch besser als den bisherigen Ansätzen.. Es existieren schon einige vortrainierte Modelle, die man nutzen kann. Die Visualisierung des Trainings kann Live eingesehen werden. Dafür bringt das Tool eigene Graphen mit. Außerdem kann TensorBoard benutzt werden – eine webbasierte Software von Tensorflow, um das Training zu kontrollieren und Insights zu erlangen.
Prediction und Evaluation. Figure 1 von NeuroNER: an easy-to-use program for named-entity recognition based on neural networks[/caption]
Bei NeuroNER liegt der Fokus auf Usability. Durch ihr Annotationstool und die enge Verzahnung zum Modelltraining gelingt das den Autoren auch besser als den bisherigen Ansätzen.. Es existieren schon einige vortrainierte Modelle, die man nutzen kann. Die Visualisierung des Trainings kann Live eingesehen werden. Dafür bringt das Tool eigene Graphen mit. Außerdem kann TensorBoard benutzt werden – eine webbasierte Software von Tensorflow, um das Training zu kontrollieren und Insights zu erlangen.
Experimente & Daten
Die Experimente sind nicht sehr umfangreich. Es existiert ein Vergleich mit dem aktuellen State-of-the-Art Ansatz:- State of the Art [Passos et al.] – CoNLL 2003: 90.9%, i2b2: 97.9%
- NeuroNER – CoNLL: 90.5%, i2b2: 97.7%
Fortführend
Für fortführende Arbeiten und Experimente bietet das Paper keine Perspektive. Lust zu lesen? Hier gehts zum Paper.Ähnliche Arbeiten
- Guergana K Savova, James J Masanz, Philip V Ogren, Jiaping Zheng, Sunghwan Sohn, Karin C KipperSchuler, and Christopher G Chute. 2010. Mayo clinical text analysis and knowledge extraction system (ctakes): architecture, component evaluation and applications. Journal of the American Medical Informatics Association 17(5):507–513.
- HC Cho, N Okazaki, M Miwa, and J Tsujii. 2010. Nersuite: a named entity recognition toolkit. Tsujii Laboratory, Department of Information Science, University of Tokyo, Tokyo, Japan .
- William Boag, Kevin Wacome, Tristan Naumann, and Anna Rumshisky. 2015. Cliner: A lightweight tool for clinical named entity recognition. American Medical Informatics Association (AMIA) Joint Summits on Clinical Research Informatics (poster) .
- Robert Leaman, Graciela Gonzalez, et al. 2008. Banner: an executable survey of advances in biomedical named entity recognition. In Pacific symposium on biocomputing. volume 13, pages 652–663.