
Paper Review stellen wir euch aktuelle Paper aus dem Bereich Machine Learning vor. Wir fassen für euch das Wesentliche zusammen und ihr entscheidet selbst, ob ihr das Paper lesen wollt oder nicht. Viel Spaß!
Main Takeaway – Was ist neu
Neuronale Netze werden häufig als Black-Boxen gesehen. Man kann die Entscheidungen des Klassifikators nicht so einfach einsehen, wie man das gern möchte. Um diese Einschränkungen aufzuheben, stellen die Autoren in dem Paper die beiden Systeme PatternNet und PatternLRP vor. Hier gehts zum Paper. Takeaways- Die Gewichte im ersten Layer zwischen Input Space und ersten Hiddenlayer sagen nicht aus, wie wichtig ein Feature ist.
- Es gibt verschiedene Ansätze, um den Zusammenhang zwischen Input und Output in neuronalen Netzen sichtbar zu machen.
Worum geht es
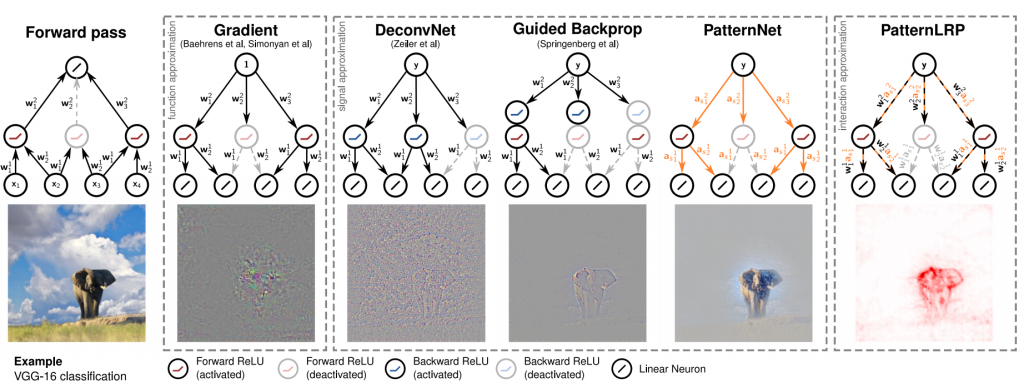 Verschiedene Ansätze, um Zusammenhänge von Input und Output zu visualisieren. Quelle: Figure 1 – PatternNet and PatternLRP Improving the interpretability of neural networks[/caption]
Verschiedene Ansätze, um Zusammenhänge von Input und Output zu visualisieren. Quelle: Figure 1 – PatternNet and PatternLRP Improving the interpretability of neural networks[/caption]
Um dem Thema näher zu kommen, werden zuerst lineare Modelle beleuchtet und bereits existierende Explanation-Methoden vorgestellt. Danach wird eine Objective Function zur Messung der Qualität von Neuronweisen Explanation-Methoden eingeführt. Basierend darauf werden zwei neue Systeme eingeführt.
Um Klassifikatorentscheidungen sichtbar zu machen, werden Methoden benutzt, die eine Rückprojektion in den Input-Space möglich machen u.a. saliency maps (Aktivierungsmuster), DeConvNet, Guided BackProp (GBP), Layer-wise Relevance Propagation (LRP) und Deep Taylor Decomposition (DTD). Dafür werden die beiden Systeme PatternNet und PatternLRP vorgeschlagen. Diese unterschieden sich in der Form der Ausgabe und benutzen jeweils verschiedene Methoden, um beispielsweise Rauschen zu minimieren.Experimente & Daten
[caption id="attachment_335" align="alignright" width="515"] Man sieht den Vergleich verschiedener Verfahren sowie deren Output (Experiment: Qualitative evaluation). Quelle: Figure 7 – PatternNet and PatternLRP Improving the interpretability of neural networks.[/caption]
Die Autoren haben 3 verschiedene Experimente durchgeführt. Größtenteils beschränkt sich die Auswertung aber auf ein qualitative Auswertung der Daten.
Man sieht den Vergleich verschiedener Verfahren sowie deren Output (Experiment: Qualitative evaluation). Quelle: Figure 7 – PatternNet and PatternLRP Improving the interpretability of neural networks.[/caption]
Die Autoren haben 3 verschiedene Experimente durchgeführt. Größtenteils beschränkt sich die Auswertung aber auf ein qualitative Auswertung der Daten.
- Measuring the quality of signal estimators – Anhand einer Correlation-Metrik wird gemessen, wie gut die Muster wiedererkannt werden. Als Baseline dient dabei eine Zufallsschätzung.
- Image degradation – Das Bild wird in 9×9 Pixel große Patches zerlegt. Danach wird die Aktivierung der der Heat-Map als Zahl gemessen und die Patches nach dem Grad der Aktivierung absteigend geordnet.
- Qualitative evaluation – Existierende und die beiden vorgestellten Verfahren wurden an den selben Bildern getestet und durch Visual Inspection (Ansehen der Bilder) die Qualität entschieden.
Fortführend
Für fortführende Arbeiten und Experimente bietet das Paper keine Perspektive. Lust zu lesen? Hier gehts zum Paper.Ähnliche Arbeiten
- Matthew D Zeiler and Rob Fergus. Visualizing and understanding convolutional networks. In European Conference on Computer Vision, pages 818–833. Springer, 2014.
- Jost Tobias Springenberg, Alexey Dosovitskiy, Thomas Brox, and Martin Riedmiller. Striving for simplicity: The all convolutional net. In ICLR, 2015.
- Luisa M Zintgraf, Taco S Cohen, Tameem Adel, and Max Welling. Visualizing deep neural network decisions: Prediction difference analysis. In ICLR, 2017
- Karen Simonyan, Andrea Vedaldi, and Andrew Zisserman. Deep inside convolutional networks: Visualising image classification models and saliency maps. In ICLR, 2014.
- Jason Yosinski, Jeff Clune, Thomas Fuchs, and Hod Lipson. Understanding neural networks through deep visualization. In ICML Workshop on Deep Learning, 2015.
- Anh Nguyen, Alexey Dosovitskiy, Jason Yosinski, Thomas Brox, and Jeff Clune. Synthesizing the preferred inputs for neurons in neural networks via deep generator networks. In Advances in Neural Information Processing Systems, pages 3387–3395, 2016.
- David Baehrens, Timon Schroeter, Stefan Harmeling, Motoaki Kawanabe, Katja Hansen, and Klaus-Robert Muller. How to explain individual classification decisions. ¨ Journal of Machine Learning Research, 11(Jun):1803–1831, 2010.
- Sebastian Bach, Alexander Binder, Gregoire Montavon, Frederick Klauschen, Klaus-Robert ´ Muller, and Wojciech Samek. On pixel-wise explanations for non-linear classifier decisions by ¨ layer-wise relevance propagation. PloS one, 10(7):e0130140, 2015.
- Gregoire Montavon, Sebastian Lapuschkin, Alexander Binder, Wojciech Samek, and Klaus- ´ Robert Muller. Explaining nonlinear classification decisions with deep taylor decomposition. ¨ Pattern Recognition, 65:211–222, 2017.